

Le travail sur les bases de données a longtemps été un secteur très centralisé. Les administrateurs de bases de données et les développeurs travaillaient côte à côte, partageaient le même réseau interne et pouvaient se passer le relais sans difficulté. Ce modèle a considérablement évolué. Les équipes sont désormais fréquememnt réparties entre différentes villes, fuseaux horaires et continents, et les pratiques qui fonctionnaient dans un environnement de bureau partagé ne se transposent pas automatiquement aux environnements distribués. Dans ce contexte, une collaboration réussie exige une conception de processus réfléchie, des conventions claires et des outils permettant de surmonter la distance physique sans compromettre la sécurité ni la cohérence.
Établir des normes communes avant de commencer à travailler ensemble
La principale source de friction au sein des équipes de bases de données distribuées réside dans le manque de cohérence : requêtes rédigées dans des styles incompatibles, conventions de nommage différentes selon les membres de l'équipe, configurations de connexion fonctionnelles sur certains postes mais pas sur d'autres. Ces problèmes s’accumulent avec le temps et deviennent de plus en plus difficiles à démêler s’ils ne sont pas traités rapidement.
La solution la plus efficace consiste à établir des normes communes avant que l'équipe ne commence à les mettre en œuvre. Cela implique de se mettre d'accord sur les conventions de formatage SQL, les règles de nommage des objets, ainsi que sur la manière de structurer et de réviser les différents types d'opérations sur la base de données (modifications du schéma, développement de requêtes, mises à jour du modèle de données). La documentation de ces normes doit être centralisée et accessible à toute l'équipe, et non pas se trouver juste dans la tête de quelqu'un ou dans des fichiers locaux.
Considérer les requêtes et les scripts comme des ressources partagées
Dans de nombreuses équipes, les requêtes et les scripts SQL sont stockés sous forme de fichiers privés sur des ordinateurs portables individuels, échangés par e-mail ou partagés via des messageries instantanées. Il est alors quasiment impossible de savoir quelle version d'une requête est à jour, qui l'a modifiée en dernier ou si un script a été testé avec des données de production. Le résultat est des efforts inutiles, des résultats incohérents et un risque important de perte de connaissances lorsque des membres de l’équipe partent.
Considérer les requêtes comme des ressources partagées et stockées de manière centralisée, à l'instar de la manière dont les équipes de développement traitent le code des applications, modifie considérablement cette dynamique. Lorsque tous les membres de l'équipe ont accès à la même bibliothèque de requêtes, les mises à jour sont visibles par tous, les doublons sont réduits et le savoir-faire institutionnel contenu dans les requêtes bien conçues est préservé au lieu d'être cloisonné.
Mettre en place des processus clairs de transmission et de révision
Les équipes distribuées rencontrent souvent des difficultés lors des passations de tâches, c'est-à-dire les moments où une personne termine sa partie du travail et qu'une autre prend le relais. Dans une équipe travaillant au même endroit, ces transitions se font naturellement par la communication orale. Dans une équipe distribuée, elles doivent être explicitées. Cela est particulièrement vrai pour les opérations critiques sur les bases de données, comme les modifications de schéma ou les migrations de données, où une hypothèse non documentée peut engendrer de graves problèmes par la suite.
La mise en place de processus de révision simplifiés, dans lesquels les modifications importantes sont examinées par au moins un autre membre de l'équipe avant d'être appliquées, permet de détecter les erreurs que l'auteur de la modification est souvent trop impliqué pour voir. Cela favorise également la diffusion des connaissances au sein de l'équipe, afin que les objets critiques de la base de données ne soient pas maîtrisés par une seule personne.
Gérer les accès avec soin selon les fuseaux horaires
Dans un environnement distribué, les membres d'une équipe situés dans différentes régions du monde accèdent inévitablement aux mêmes systèmes de bases de données à des moments différents, parfois sans qu'un collègue ne soit disponible pour intervenir en cas de problème. Cela rend le contrôle des accès encore plus crucial que dans un environnement regroupant des ressources sur un même site. Le principe du moindre privilège, c'est-à-dire le fait de n'accorder à chaque membre de l'équipe l'accès qu'aux éléments nécessaires à son rôle, limite l'ampleur des conséquences des erreurs commises en dehors des heures de travail, lorsque la supervision est minimale. Une documentation claire indiquant qui a accès à quoi et pourquoi facilite également la révision et la mise à jour des autorisations à mesure que l'équipe évolue.
Comment Navicat On-Prem Server 3.1 facilite le travail des équipes dispersées
Navicat On-Prem Server 3.1 est conçu spécifiquement pour répondre aux défis de collaboration rencontrés par les équipes travaillant sur des bases de données distribuées. Sa fonction principale est de servir de hub privé et auto-hébergé permettant aux membres de l'équipe de partager les objets qu'ils utilisent quotidiennement : paramètres de connexion, requêtes, extraits de code, modèles de données, pipelines d'agrégation et espaces de travail décisionnels. Comme le serveur fonctionne sur l'infrastructure propre à l'organisation plutôt que sur un service cloud tiers, les équipes soumises à des exigences strictes en matière de gouvernance des données peuvent bénéficier des avantages d'une plateforme partagée en matière de collaboration sans avoir à acheminer les objets de base de données internes via des systèmes externes.
La plateforme organise le travail en projets, chacun disposant de ses propres membres et contrôles d'accès. Les membres de l'équipe se voient attribuer l'un des trois rôles suivants : « Peut gérer et modifier », « Peut modifier » ou « Peut consulter », ce qui permet de définir précisément ce que chacun est autorisée à faire au sein du projet. Ce système s'inscrit directement dans le principe du moindre privilège et permet d'attribuer facilement aux contributeurs distants les accès nécessaires à leur rôle, sans autorisations superflues..
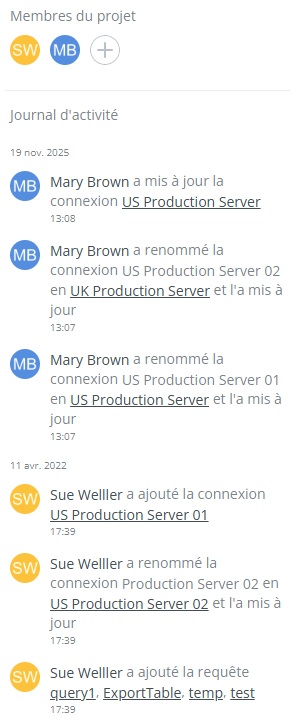
L'une des fonctionnalités les plus utiles en pratique pour les équipes distribuées est le journal d'activité en temps réel, qui enregistre toutes les actions collaboratives réalisées au sein d'un projet. Lorsque les membres de l'équipe travaillent dans des fuseaux horaires différents et ne peuvent pas toujours communiquer de manière synchrone, le journal d'activité offre une visibilité sur ce qui a été modifié, qui l'a modifié et quand, créant ainsi la trace écrite indispensable à la passation de tâches.
La plateforme prend également en charge les notifications par SMS et par e-mail pour les invitations à des projets, les événements de sécurité et les mises à jour du serveur, permettant ainsi aux membres d'une équipe distribuée de rester informés sans avoir à surveiller constamment l'interface.
Pour les organisations qui gèrent leurs utilisateurs via un système d'identité centralisé, Navicat On-Prem Server 3.1 prend en charge l'authentification via LDAP et Microsoft Active Directory. Ainsi, la gestion des comptes utilisateurs (création et suppression) peut être effectuée via l'infrastructure informatique existante plutôt que séparément sur la plateforme. Tous les clients de bureau Navicat – sous Windows, macOS et Linux – peuvent se connecter au serveur, ce qui permet aux membres de l'équipe travaillant sur différents systèmes d'exploitation de participer au même environnement de collaboration sans aucune limitation liée à la plateforme. La version 3.1 a également intégré les fonctionnalités Assistant IA et Ask AI, rendant ainsi la rédaction et l'explication de requêtes assistées par l'IA disponibles pour la première fois dans l'environnement sur site.
Conclusion
Une collaboration efficace autour des bases de données dans un environnement distribué ne se fait pas automatiquement. Elle exige un investissement délibéré dans des normes partagées, des ressources centralisées, des processus clairs et des contrôles d'accès adaptés aux réalités d'une équipe dispersée. Les équipes qui réussissent le mieux sont généralement celles qui considèrent la collaboration comme une priorité stratégique, plutôt que comme un problème à résoudre au fil de l’eau, et qui soutiennent cette approche avec des outils réellement conçus pour un contexte distribué, plutôt que simplement adaptés à partir d’un environnement traditionnel.




