

Pendant des années, de nombreuses organisations se sont appuyées sur de simples contrôles de disponibilité (uptime) pour évaluer la santé de leurs bases de données. S'il est certes important de savoir que votre base de données fonctionne, la disponibilité seule ne vous renseigne quasiment pas sur ses performances, son efficacité ou l'expérience utilisateur. Une base de données peut techniquement être « opérationnelle » tout en fournissant des requêtes extrêmement lentes, en souffrant de conflits de ressources ou en étant au bord de la saturation. La surveillance moderne des bases de données exige une approche plus sophistiquée, axée sur les métriques qui ont un réel impact sur vos applications et vos utilisateurs.
Indicateurs de performances des requêtes
Le domaine le plus critique à surveiller est celui des performances des requêtes, car c'est au niveau des requêtes que votre base de données interagit directement avec vos applications. Les requêtes longues sont souvent le signe avant-coureur de problèmes plus profonds. En suivant les temps d'exécution des requêtes, vous pouvez identifier celles qui consomment des ressources excessives et créent des goulots d'étranglement. Il est tout aussi important de comprendre les temps d’attente des requêtes, qui révèlent ce qu’elles attendent réellement : accès disque, verrous, ressources réseau, etc.
Au-delà du temps d’exécution, l’analyse des requêtes les plus consommatrices de CPU permet d’identifier les opérations les plus coûteuses en calcul. De même, le suivi des requêtes en fonction du nombre de lectures et d'écritures effectuées peut mettre en évidence des schémas d'accès aux données inefficaces, susceptibles de bénéficier d'une optimisation des index ou d'une refactorisation des requêtes. Ces indicateurs transforment des problèmes de performance abstraits en informations concrètes et exploitables.
Utilisation des ressources et capacité
Bien que l'utilisation du processeur et de la mémoire puisse sembler être des mesures élémentaires, il est essentiel de les comprendre dans leur contexte. Les modèles d'utilisation du processeur vous indiquent si votre serveur de base de données dispose d'une puissance de traitement suffisante pour votre charge de travail, mais surtout, une utilisation élevée et soutenue du processeur peut indiquer des index manquants ou des requêtes mal optimisées plutôt qu'un simple manque de matériel.
Les métriques de mémoire méritent une attention particulière, car les bases de données s'appuient fortement sur la mise en cache pour offrir de bonnes performances. Le taux d'accès au cache, qui mesure le pourcentage de requêtes de données traitées depuis la mémoire plutôt que depuis le disque, devrait généralement dépasser 90 %. Lorsque ce taux diminue, cela indique que votre base de données accède fréquemment au disque pour récupérer des données, ce qui ralentit considérablement les performances. La surveillance de l'allocation de mémoire au fil du temps facilite également la planification de la capacité, en vous indiquant si l'empreinte mémoire de votre base de données augmente à un rythme soutenable.
Les métriques d'E/S disque complètent l'analyse des ressources. Le suivi des opérations de lecture et d'écriture disque par seconde, ainsi que des temps de réponse moyens du disque, permet de déterminer si le stockage devient un goulot d'étranglement. Les E/S réseau sont tout aussi importantes pour comprendre le volume de données transitant entre votre base de données et vos applications.
Activité des connexions et des sessions
La surveillance des connexions actives et des détails de session offre une visibilité sur la manière dont vos applications utilisent réellement la base de données. Le suivi des connexions utilisateur actuelles vous aide à comprendre votre charge de travail simultanée et peut vous alerter lorsque le pool de connexions est épuisé avant que cela ne provoque des défaillances de l'application. L'analyse des schémas de connexion au fil du temps met également en évidence des tendances d'utilisation utiles pour les décisions de planification de la capacité.
La surveillance des verrous est particulièrement importante pour comprendre les problèmes de contention. Lorsque les requêtes attendent des verrous détenus par d'autres sessions, les utilisateurs subissent des délais que de simples indicateurs de CPU ou de mémoire ne peuvent expliquer. En suivant à la fois les verrous actuellement détenus et les sessions en attente de verrous, vous pouvez identifier des schémas de transactions problématiques ou des transactions de longue durée qui bloquent les autres opérations.
Mesurer ces indicateurs avec Navicat Monitor
Navicat Monitor offre une architecture sans agent pour la surveillance des bases de données MySQL, MariaDB, PostgreSQL et SQL Server. Vous n'avez donc pas besoin d'installer de logiciel sur vos serveurs de bases de données. L'outil collecte les métriques à intervalles réguliers et les stocke dans une base de données de référence pour l'analyse historique et le suivi des tendances.
Pour la surveillance des performances des requêtes, le graphique « Requêtes longues » de Navicat Monitor visualise les requêtes les plus gourmandes en ressources en fonction de leur durée d'exécution, des types d'attente, de l'utilisation du processeur et des opérations de lecture/écriture. Cela vous permet d’identifier rapidement les requêtes problématiques et d'examiner en détail leurs caractéristiques d’exécution. L’outil conserve des données historiques afin de suivre l’évolution des performances des requêtes et de détecter toute dégradation au fil du temps.
La surveillance des ressources dans Navicat Monitor couvre l’ensemble des indicateurs système. Elle collecte la charge du processeur, l'utilisation de la RAM et diverses autres ressources système via SSH ou SNMP, offrant ainsi une visibilité complète sur les performances au niveau de la base de données et du système d'exploitation. Le tableau de bord interactif fournit des graphiques en temps réel et historiques indiquant la charge du serveur, l'utilisation du disque, les E/S réseau et les verrous de table, ce qui facilite la corrélation entre les différents indicateurs et l'identification de tendances.
L'une des fonctionnalités les plus puissantes est la possibilité de créer des métriques personnalisées. Vous pouvez écrire vos propres requêtes pour collecter des indicateurs de performance sur des instances spécifiques et recevoir des alertes lorsque les valeurs dépassent des seuils définis. Vous pouvez ainsi surveiller des indicateurs métier ou des caractéristiques de performance spécifiques à vos applications, allant bien au-delà des métriques prédéfinies standard.
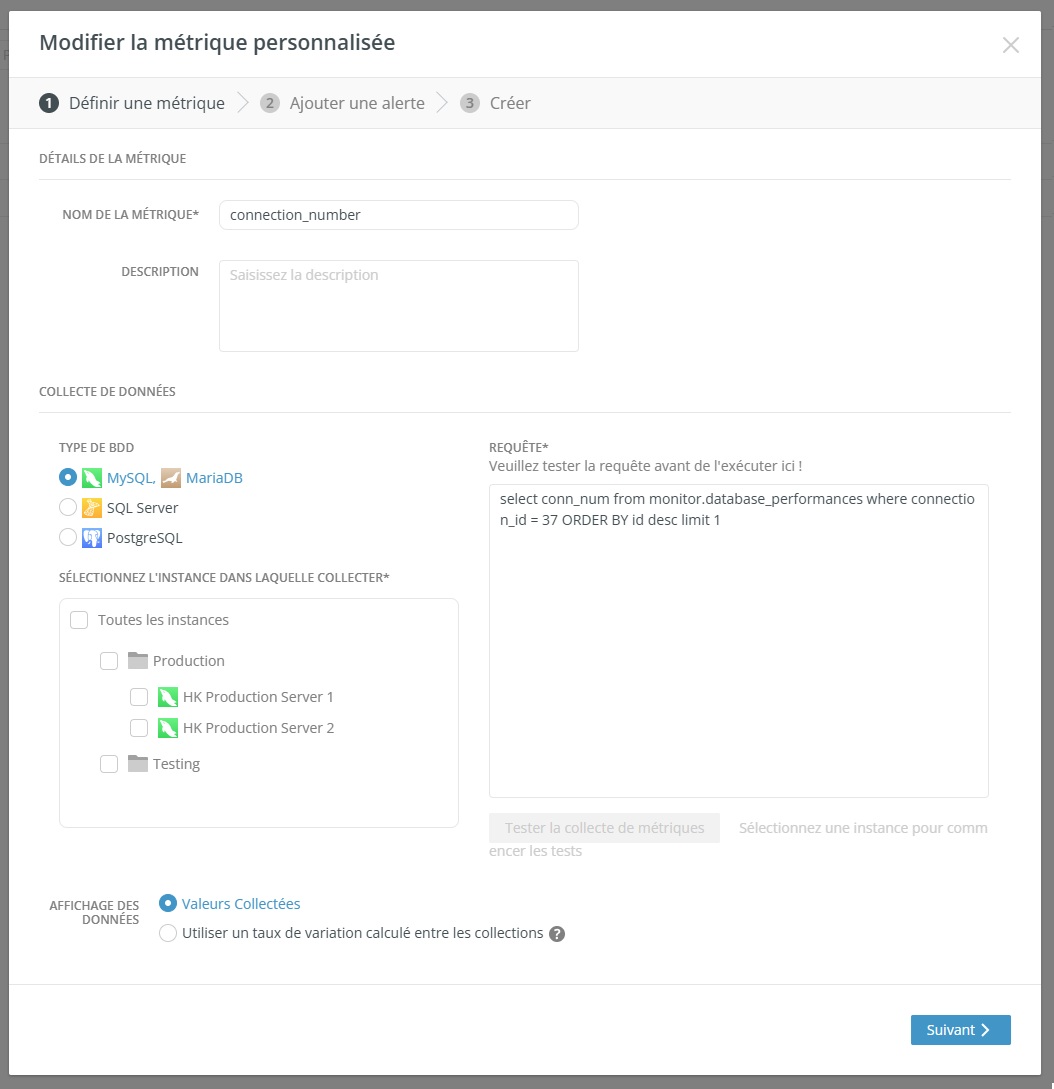
Le système d'alerte de Navicat Monitor permet une gestion proactive en vous informant lorsque les métriques dépassent des seuils configurables. Vous pouvez définir des alertes pour n’importe quelle métrique y compris les métriques personnalisées, et définir à la fois la valeur seuil et la durée pendant laquelle elle doit être dépassée avant le déclenchement de l’alerte. Les notifications peuvent être envoyées par e-mail, SMS, SNMP ou Slack, ce qui permet à votre équipe d'être informée des problèmes avant qu'ils n'aient un impact sur les utilisateurs. L'outil fournit une analyse détaillée des alertes, incluant des graphiques, des chronologies et un contexte historique pour faciliter l'analyse des causes profondes.
Au-delà du tableau de bord : rendre les métriques exploitables
La collecte de métriques n'est que la première étape. La véritable valeur ajoutée réside dans la compréhension des tendances, la définition de références appropriées et la création d'alertes exploitables. Plutôt que de simplement surveiller les tableaux de bord, établissez des plages de valeurs normales pour vos indicateurs clés en fonction des données historiques et des modèles de charge de travail. Cela vous permet de définir des seuils d'alerte intelligents qui détectent les problèmes réels sans générer de fausses alertes dues à des variations normales.
Lors de l’analyse des incidents, il est essentiel de prendre en compte les relations entre les différents indicateurs. Une augmentation soudaine des E/S disque peut être corrélée à une baisse du taux d'accès au cache et à une augmentation des temps d'exécution des requêtes. Comprendre ces liens vous aide à identifier les causes profondes plutôt que les simples symptômes. Des examens réguliers de la planification des capacités, basées sur l'historique des tendances, vous permettent d'adapter vos ressources de manière proactive avant d'atteindre les limites de vos capacités.
Le passage d'une simple surveillance du temps de fonctionnement à une surveillance complète des performances aura un impact significatif sur la façon dont vous comprendrez et gérez vos bases de données. En vous concentrant sur les métriques qui ont un impact direct sur les performances des applications et l'expérience utilisateur, vous pouvez passer d'une approche réactive à une optimisation proactive, garantissant ainsi des performances constantes et fiables pour vos bases de données.




