

Une colonne de tableau, telle qu'une colonne qui stocke les prénoms, peut contenir de nombreuses valeurs en double. Si vous souhaitez répertorier les différentes valeurs (distinctes), il doit y avoir un moyen de le faire sans recourir à des instructions SQL complexes. Dans les bases de données compatibles ANSI SQL telles que PostgreSQL, SQL Server et MySQL, la manière de sélectionner uniquement les valeurs distinctes d'une colonne consiste à utiliser la clause SQL DISTINCT. Elle supprime les doublons des résultats d'une instruction SELECT, ne laissant que des valeurs uniques. Dans cet article de blog, nous apprendrons comment l'utiliser.
Syntaxe et comportement
Pour utiliser la clause SQL DISTINCT, il vous suffit d'insérer le mot-clé DISTINCT entre SELECT et la liste des colonnes et/ou expressions comme ceci :
SELECT DISTINCT columns/expressions FROM tables [WHERE conditions];
Vous pouvez inclure une ou plusieurs colonnes et/ou expressions dans votre instruction, car la requête utilise la combinaison de valeurs dans toutes les colonnes spécifiées de la liste SELECT pour évaluer leur unicité. De plus, si vous appliquez la clause DISTINCT à une colonne contenant des valeurs NULL, la clause DISTINCT ne conservera qu'un seul NULL et éliminera les autres. En d'autres termes, la clause DISTINCT traite toutes les valeurs NULL comme la même valeur.
Exemple avec une seule colonne
Un cas d’utilisation courant d’une requête consiste à répertorier toutes les villes et/ou pays des clients ou utilisateurs d’une organisation. Voici une requête dans Navicat Premium 16 sur l'exemple de base de données classicmodels:
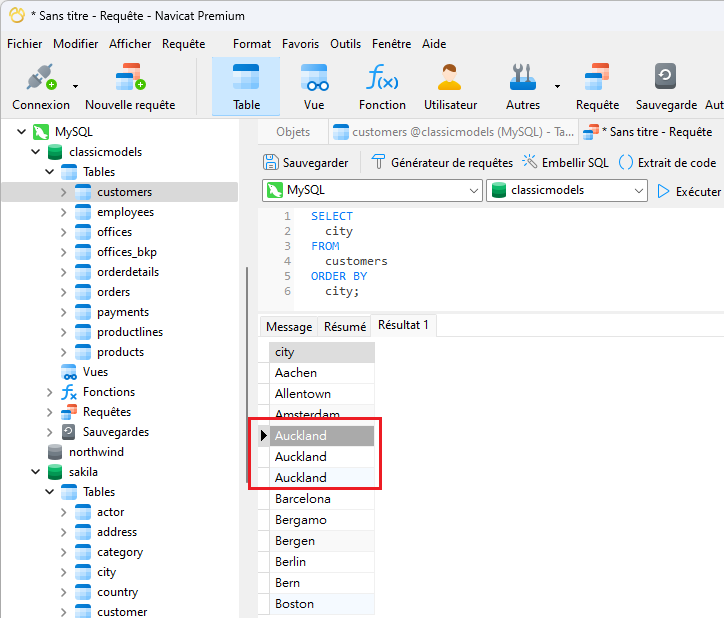
Comme souligné dans les valeurs entourées en rouge, il existe des villes en double.
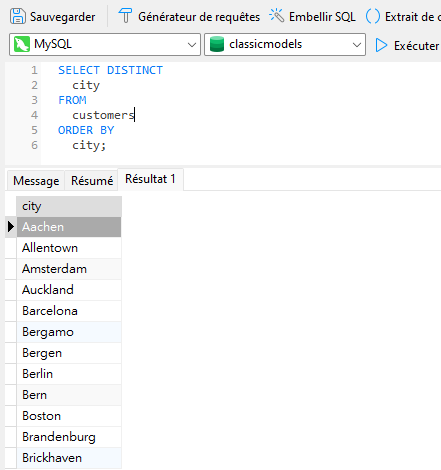
Pour obtenir une liste de villes uniques, nous pouvons ajouter le mot-clé DISTINCT à l'instruction SELECT :
Nous pouvons utiliser la fonction de complétion de code de Navicat pour afficher le mot-clé DISTINCT. Navicat affiche des informations dans des listes déroulantes au fur et à mesure que vous tapez votre instruction SQL dans l'éditeur, il vous aide à compléter l'instruction et les propriétés disponibles des objets de base de données, par exemple des bases de données, des tables, des champs, des vues, etc. avec leurs icônes appropriées :
Exemple avec plusieurs colonnes
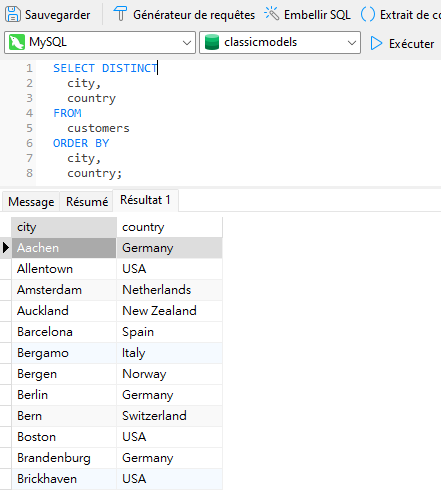
Le mot-clé DISTINCT peut également être appliqué à plusieurs colonnes. Dans ce contexte, la requête ne renverra que les lignes dont toutes les colonnes sélectionnées sont uniques. Tout d'abord, ajoutons le champ country à notre dernière requête :
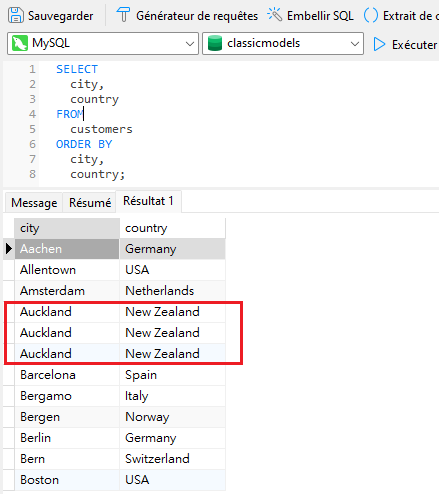
Une fois de plus, nous constatons des doublons, ce qui est logique car une ville dupliquée résidera probablement dans le même pays.
Encore une fois, l'ajout du mot-clé DISTINCT amènera le moteur de requête à examiner la combinaison de valeurs dans les colonnes de ville et de pays pour évaluer et supprimer les doublons:
Clause DISTINCT avec des valeurs nulles
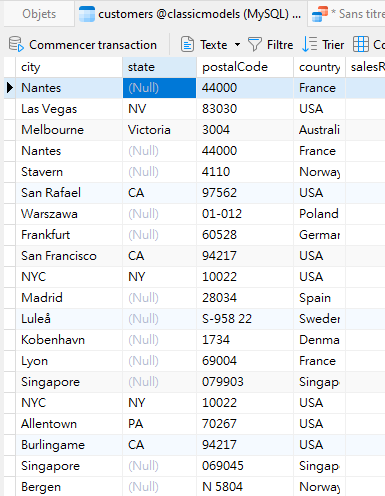
Comme indiqué ci-dessus, la clause DISTINCT traite toutes les valeurs NULL comme la même valeur afin qu'une seule instance de NULL ne soit incluse dans le résultat. Nous pouvons tester cela par nous-mêmes en interrogeant une colonne comme celle-ci dans la même table clients que celle que nous avons interrogée précédemment:
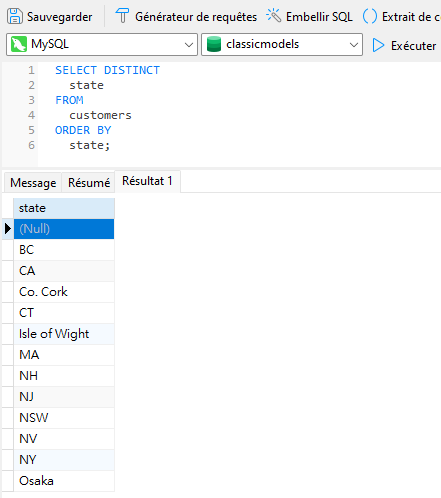
Comme prévu, l'ajout du mot-clé DISTINCT a supprimé toutes les instances de NULL sauf une:
Réflexions finales sur la sélection de valeurs distinctes à partir d'une base de données relationnelle
Dans cet article de blog, nous avons appris à utiliser la clause SQL DISTINCT, qui supprime les doublons du jeu de résultats d'une instruction SELECT, ne laissant que des valeurs uniques. Comme nous l'avons vu, il peut fonctionner sur une ou plusieurs colonnes ainsi que sur des valeurs NULL. Cependant, si vous devez appliquer une fonction d'agrégation sur une ou plusieurs colonnes, vous devez plutôt utiliser la clause GROUP BY.





