

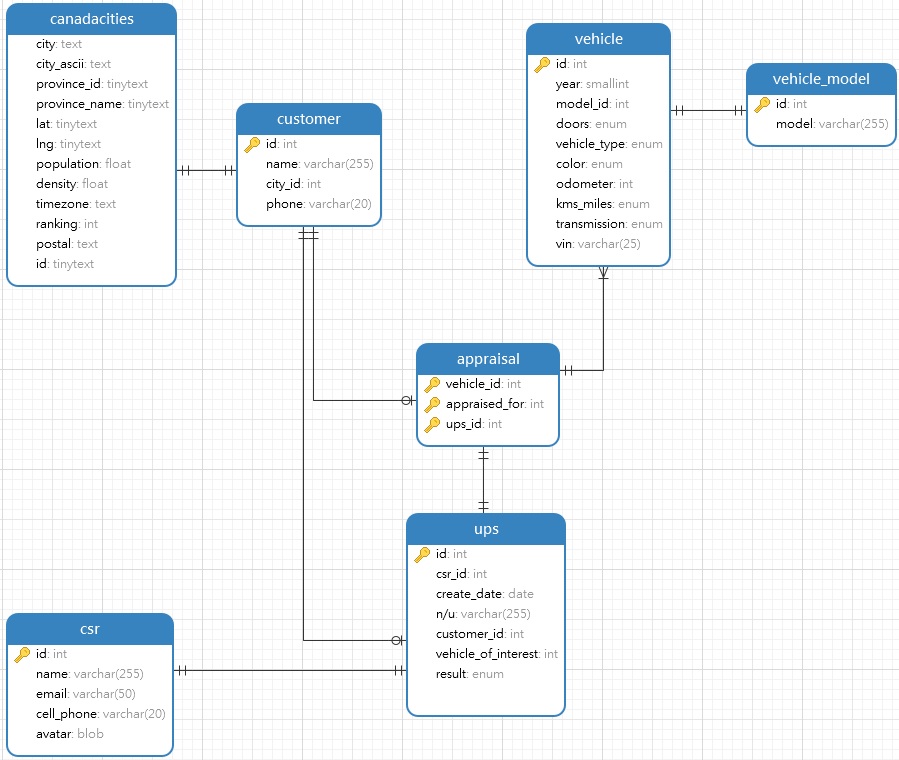
Dans le cadre du processus de normalisation des tables de base de données, les colonnes redondantes sont extraites des tables de niveau supérieur vers des tables subsidiaires distinctes. Cela se produit souvent parce que certains champs ont une relation un-à-plusieurs (one-to-many en anglais) avec l'entité mère. Par exemple, prenons le modèle suivant généré à l'aide de Navicat Data Modeler:
Alors que la plupart des systèmes de bases de données utilisent des verrous pour la gestion des accès simultanés, PostgreSQL fait les choses un peu différemment : il maintient la cohérence des données en utilisant un modèle multi-version, également connu sous le nom de contrôle des accès concurrents (Multi version concurrency control ou MVCC en abrégé). Par conséquent, lors de l’interrogation d’une base de données, chaque transaction voit un instantané des données telles qu’elles étaient quelque temps auparavant, quel que soit l’état actuel des données sous-jacentes. Cela empêche la transaction d'afficher des données incohérentes qui pourraient être provoquées par d'autres mises à jour de transactions simultanées sur les mêmes données. Cela fournit une isolation des transactions pour chaque session de base de données. Cet article du blog fournira un bref aperçu du fonctionnement du protocole MVCC et couvrira certains des avantages et des inconvénients de l'approche MVCC.
En haut de l'écran de l'analyseur de requêtes de Navicat Monitor 3, vous trouverez un graphique qui montre les requêtes dont les temps d'attente sont les plus longs.
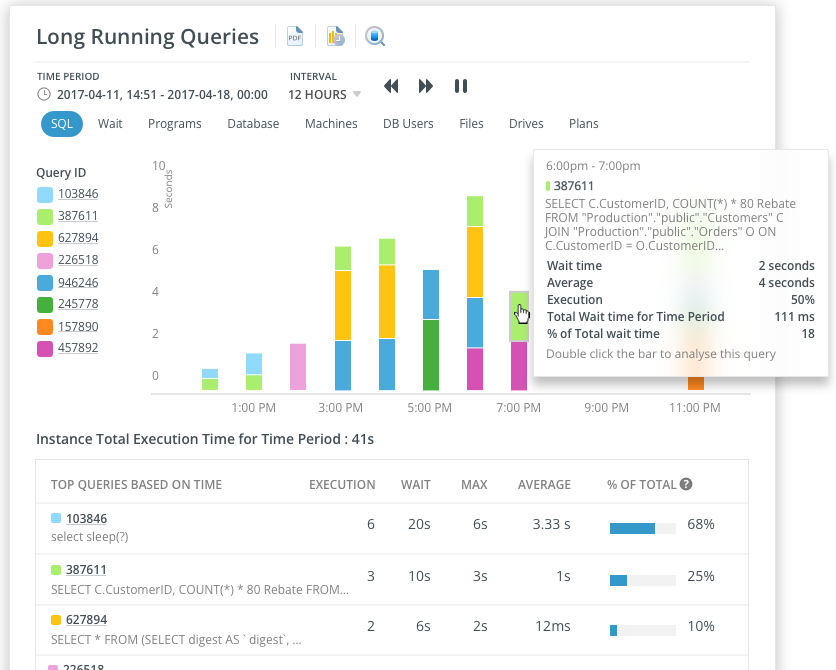
Il est essentiel d'identifier les requêtes lentes, car elles pourraient faire crasher le système.
L'idée derrière l'audit de base de données est de savoir qui a accédé aux tables de votre base de données et quand, ainsi que les modifications qui y ont été apportées. Il s'agit non seulement d'une exigence minimale standard pour toute application d'entreprise, mais également d'une exigence légale pour de nombreux domaines tels que la banque et la cybersécurité. Les journaux d'audit de base de données sont essentiels pour investiguer sur toutes sortes de problèmes d'application tels que les accès non autorisés, les modifications de configuration et bien d'autres choses encore.
Dans le blog d'aujourd'hui, nous allons ajouter un log à la base de données MySQL Sakila Sample Database afin d’auditer la table Location. C'est une table-clé car la base de données représente les processus métiers d'un magasin de location de DVD.
Une colonne de tableau, telle qu'une colonne qui stocke les prénoms, peut contenir de nombreuses valeurs en double. Si vous souhaitez répertorier les différentes valeurs (distinctes), il doit y avoir un moyen de le faire sans recourir à des instructions SQL complexes. Dans les bases de données compatibles ANSI SQL telles que PostgreSQL, SQL Server et MySQL, la manière de sélectionner uniquement les valeurs distinctes d'une colonne consiste à utiliser la clause SQL DISTINCT. Elle supprime les doublons des résultats d'une instruction SELECT, ne laissant que des valeurs uniques. Dans cet article de blog, nous apprendrons comment l'utiliser.





